
软件介绍
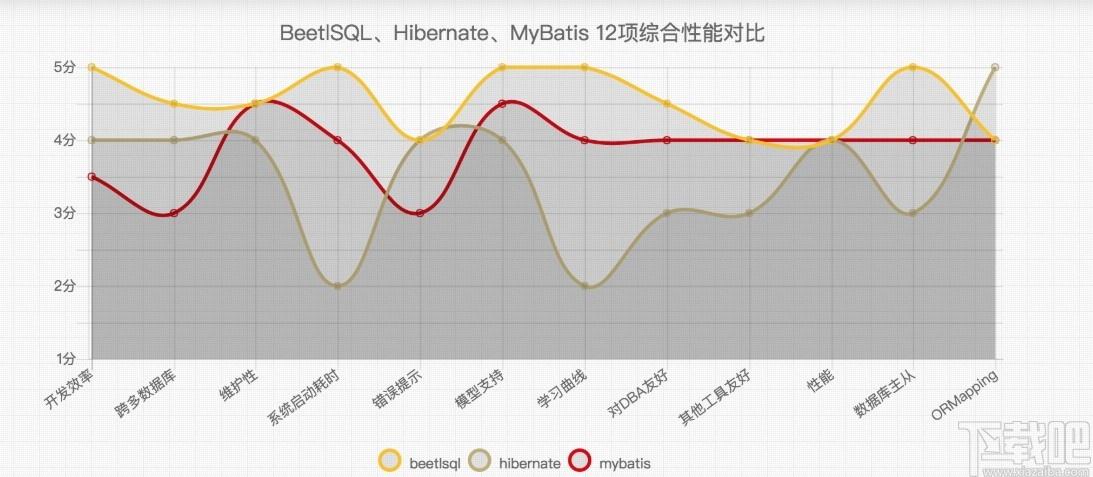
BeetSql是一个功能强大、简单易用的数据库管理工具,集Hibernate、Mybatis等多种优点于一身,是一款功能丰富齐全、专业实用的DAO工具,适用于以SQL为中心且又能自动能生成大量常用的SQL的应用,是一款专门针对程序编程、数据库设计的用户而设计研发,非常方便实用;BeetSql这款数据库管理软件,开发效率高、跨多数据库、对DBA友好,同时指出语法高亮、错误提示、模型指出等多种功能,可以帮助用户减少代码数据库代码编辑错误、提高数据库设计和数据库管理效率,是一款不可多得的数据库管理软件。
软件功能
BeetlSQL的目标是提供开发高效,维护高效,运行高效的数据库访问框架,在一个系统多个库的情况下,提供一致的编写代码方式。支持如下数据平台
传统数据库:MySQL,MariaDB,Oralce,Postgres,DB2,SQLServer,H2,SQLite,Derby,神通,达梦,华为高斯,人大金仓,PolarDB等
大数据:HBase,ClickHouse,Cassandar,Hive
物联网时序数据库:Machbase,TD-Engine,IotDB
SQL查询引擎:Drill,Presto,Druid
内存数据库:ignite,CouchBase
BeetlSQL不仅仅是简单的类似MyBatis或者是Hibernate,或者是俩着的综合,BeetlSQL远大理想是对标甚至超越SpringData,是实现数据访问统一的框架,无论是传统数据库,还是大数据,还是查询引擎或者时序库,内存数据库。
软件特色
简单易用
简单易用Beetl类似Javascript语法和习俗,只要半小时就能通过半学半猜完全掌握用法。拒绝其他模板引擎那种非人性化的语法和习俗。同时也能支持html标签,使得开发CMS系统比较容易
易于整合
Beetl能很容易的与各种web框架整合,如ActFramework,SpringMVC,Struts,Nutz,Jodd,Servlet,JFinal等。支持模板单独开发和测试,即在MVC架构中,即使没有M和C部分,也能开发和测试模板。
性能卓越
Beetl远超过主流java模板引擎性能(引擎性能5-6倍与freemaker,2倍于JSP),宏观上通过了优化的渲染引擎,IO的二进制输出,字节码属性访问增强,微观上通过一维数组保存上下文Context,静态文本合并处理,重复使用字节数组来防止java频繁的创建和销毁数组,还使用模板缓存,运行时优化等方法。
开发效率高
无需注解,自动使用大量内置SQL,轻易完成增删改查功能,节省50%的开发工作量。数据模型支持Pojo,也支持Map/List这种快速模型,也支持混合模型。SQL模板基于Beetl实现,更容易写和调试,以及扩展。可以针对单个表(或者视图)代码生成pojo类和sql模版,甚至是整个数据库。能减少代码编写工作量。
易于维护SQL
以更简洁的方式,Markdown方式集中管理,同时方便程序开发和数据库SQL调试。可以自动将sql文件映射为dao接口类。灵活直观的支持支持一对一,一对多,多对多关系映射而不引入复杂的ORMapping概念和技术。具备Interceptor功能,可以调试,性能诊断SQL,以及扩展其他功能
其他特色
内置支持主从数据库支持的开源工具,支持跨数据库平台,开发者所需工作减少到最小,目前跨数据库支持MySql、Postgres、Oracle、SQLServer、h2、SQLite、DB2、CLickhouse、HBase,Cassandar、Hive、TD-Engine,Drill、Presto、ignite、CouchBase等
安装方法
com.ibeetl
beetlsql
2.13.0.RELEASE
com.ibeetl
beetl
${最新版本}
或者依次下载beetlsql,beetl最新版本包放到classpath里
准备工作为了快速尝试BeetlSQL,需要准备一个Mysql数据库或者其他任何beetlsql支持的数据库,然后执行如下sql脚本
CREATETABLE`user`(
`id`int(11)NOTNULLAUTO_INCREMENT,
`name`varchar(64)DEFAULTNULL,
`age`int(4)DEFAULTNULL,
`create_date`datetimeNULLDEFAULTNULL,
PRIMARYKEY(`id`)
)ENGINE=InnoDBDEFAULTCHARSET=utf8;
编写一个Pojo类,与数据库表对应(或者可以通过SQLManager的gen方法生成此类,参考一下节)
importjava.math.*;
importjava.util.Date;
/*
*
*genbybeetlsql2016-01-06
*/
publicclassUser{
privateIntegerid;
privateIntegerage;
privateStringname;
privateDatecreateDate;
}
主键需要通过注解来说明,如@AutoID,或者@AssignID等,但如果是自增主键,且属性是名字是id,则不需要注解,自动认为是自增主键
代码例子写一个java的Main方法,内容如下
ConnectionSourcesource=ConnectionSourceHelper.getSimple(driver,url,userName,password);
DBStylemysql=newMySqlStyle();
//sql语句放在classpagth的/sql目录下
SQLLoaderloader=newClasspathLoader("/sql");
//数据库命名跟java命名一样,所以采用DefaultNameConversion,还有一个是UnderlinedNameConversion,下划线风格的,
UnderlinedNameConversionnc=newUnderlinedNameConversion();
//最后,创建一个SQLManager,DebugInterceptor不是必须的,但可以通过它查看sql执行情况
SQLManagersqlManager=newSQLManager(mysql,loader,source,nc,newInterceptor[]{newDebugInterceptor()});
//使用内置的生成的sql新增用户,如果需要获取主键,可以传入KeyHolder
Useruser=newUser();
user.setAge(19);
user.setName("xiandafu");
sqlManager.insert(user);
//使用内置sql查询用户
intid=1;
user=sqlManager.unique(User.class,id);
//模板更新,仅仅根据id更新值不为null的列
UsernewUser=newUser();
newUser.setId(1);
newUser.setAge(20);
sqlManager.updateTemplateById(newUser);
//模板查询
Userquery=newUser();
query.setName("xiandafu");
Listlist=sqlManager.template(query);
//Query查询
QueryuserQuery=sqlManager.getQuery(User.class);
Listusers=userQuery.lambda().andEq(User::getName,"xiandafy").select();
//使用user.md文件里的select语句,参考下一节。
Userquery2=newUser();
query.setName("xiandafu");
Listlist2=sqlManager.select("user.select",User.class,query2);
//这一部分需要参考mapper一章
UserDaodao=sqlManager.getMapper(UserDao.class);
Listlist3=dao.select(query2);
BeetlSql2.8.11提供了SQLManagerBuilder来链式创建SQLManager
SQL文件例子通常一个项目还是有少量复杂sql,可能只有5,6行,也可能有上百行,放在单独的sql文件里更容易编写和维护,为了能执行上例的user.select,需要在classpath里建立一个sql目录(在src目录下建立一个sql目录,或者maven工程的resources目录。ClasspathLoader配置成sql目录,参考上一节ClasspathLoader初始化的代码)以及下面的user.md文件,内容如下
select
===
select*fromuserwhere1=1
@if(!isEmpty(age)){
andage=#age#
@}
@if(!isEmpty(name)){
andname=#name#
@}
关于如何写sql模板,会稍后章节说明,如下是一些简单说明。
采用md格式,===上面是sql语句在本文件里的唯一标示,下面则是sql语句。
@和回车符号是定界符号,可以在里面写beetl语句。
"#"是占位符号,生成sql语句得时候,将输出?,如果你想输出表达式值,需要用text函数,或者任何以db开头的函数,引擎则认为是直接输出文本。
isEmpty是beetl的一个函数,用来判断变量是否为空或者是否不存在.
文件名约定为类名,首字母小写。
sql模板采用beetl原因是因为beetl语法类似js,且对模板渲染做了特定优化,相比于mybatis,更加容易掌握和功能强大,可读性更好,也容易在java和数据库之间迁移sql语句
注意:sqlId到sql文件的映射是通过类SQLIdNameConversion来完成的,默认提供了DefaultSQLIdNameConversion实现,即以"."区分最后一部分是sql片段名字,前面转为为文件相对路径,如sqlId是user.select,则select是sql片段名字,user是文件名,beetlsql会在根目录下寻找/user.sql,/user.md,也会找数据库方言目录下寻找,比如如果使用了mysql数据库,则优先寻找/mysql/user.md,/mysql/user.sql然后在找/user.md,/user.sql.
如果sql是test.user.select,则会在/test/user.md(sql)或者/mysql/test/user.md(sql)下寻找“select”片段
代码&sql生成User类并非需要自己写,好的实践是可以在项目中专门写个类用来辅助生成pojo和sql片段,代码如下
publicstaticvoidmain(String[]args){
SqlManagersqlManager=......//同上面的例子
sqlManager.genPojoCodeToConsole("user");
sqlManager.genSQLTemplateToConsole("user");
}
注意:我经常在我的项目里写一个这样的辅助类,用来根据表或者视图生成各种代码和sql片段,以快速开发.
genPojoCodeToConsole方法可以根据数据库表生成相应的Pojo代码,输出到控制台,开发者可以根据这些代码创建相应的类,如上例子,控制台将输出
packagecom.test;
importjava.math.*;
importjava.util.Date;
importjava.sql.Timestamp;
/*
*
*genbybeetlsql2016-01-06
*/
publicclassUser{
privateIntegerid;
privateIntegerage;
privateStringname;
privateDatecreateDate;
}
注意生成属性的时候,id总是在前面,后面依次是类型为Integer的类型,最后面是日期类型,剩下的按照字母排序放到中间。
一旦有了User类,如果你需要写sql语句,那么genSQLTemplateToConsole将是个很好的辅助方法,可以输出一系列sql语句片段,你同样可以赋值粘贴到代码或者sql模板文件里(user.md),如上例所述,当调用genSQLTemplateToConsole的时候,生成如下
sample
===
*注释
select#use("cols")#fromuserwhere#use("condition")#
cols
===
id,name,age,create_date
updateSample
===
`id`=#id#,`name`=#name#,`age`=#age#,`create_date`=#date#
condition
===
1=1
@if(!isEmpty(name)){
and`name`=#name#
@}
@if(!isEmpty(age)){
and`age`=#age#
@}
beetlsql生成了用于查询,更新,条件的sql片段和一个简单例子。你可以按照你的需要copy到sql模板文件里.实际上,如果你熟悉gen方法,你可以直接gen代码和sql到你的工程里,甚至是整个数据库都可以调用genAll来一次生成
注意sql片段的生成顺序按照数据库表定义的顺序显示
使用方法
BeetlSQL说明获得SQLManagerSQLManager是系统的核心,他提供了所有的dao方法。获得SQLManager,可以直接构造SQLManager.并通过单例获取如:
ConnectionSourcesource=ConnectionSourceHelper.getSimple(driver,url,"",userName,password);
DBStylemysql=newMySqlStyle();
//sql语句放在classpagth的/sql目录下
SQLLoaderloader=newClasspathLoader("/sql");
//数据库命名跟java命名一样,所以采用DefaultNameConversion,还有一个是UnderlinedNameConversion,下划线风格的
UnderlinedNameConversionnc=newUnderlinedNameConversion();
//最后,创建一个SQLManager,DebugInterceptor不是必须的,但可以通过它查看sql执行情况
SQLManagersqlManager=newSQLManager(mysql,loader,source,nc,newInterceptor[]{newDebugInterceptor()});
更常见的是,已经有了DataSource,创建ConnectionSource可以采用如下代码
ConnectionSourcesource=ConnectionSourceHelper.getSingle(datasource);
如果是主从Datasource
ConnectionSourcesource=ConnectionSourceHelper.getMasterSlave(master,slaves)
关于使用Sharding-JDBC实现分库分表,参考主从一章
查询API简单查询(自动生成sql)publicTunique(Classclazz,Objectpk)根据主键查询,如果未找到,抛出异常.
publicTsingle(Classclazz,Objectpk)根据主键查询,如果未找到,返回null.
publicListall(Classclazz)查询出所有结果集
publicListall(Classclazz,intstart,intsize)翻页
publicintallCount(Classclazz)总数
(Query)单表查询SQLManager提供Query类可以实现单表查询操作
SQLManagersql=...
Listlist=sql.query(User.class).andEq("name","hi").orderBy("create_date").select();
sql.query(User.class)返回了Query类用于单表查询
如果是Java8,则可以使用lambda表示列名
Listlist1=sql.lambdaQuery(User.class).andEq(User::getName,"hi").orderBy(User::getCreateDate).select();
lamdba()方法返回了一个LamdbaQuery类,列名支持采用lambda。
关于Query操作的具体用法,请参考25.1节
Query对象通常适合在业务操作中使用,而不能代替通常的前端界面查询,前端界面查询推荐使用sqlId来查询
Query提供俩个静态方法filterEmpty,filterNull,这俩个方法返回StrongValue的子类,当andEq等方法的参数是StrongValue子类的时候,将根据条件拼接SQL语句。StrongValue定义如下
publicinterfaceStrongValue{
/**
*value是否是一个有效的值
*返回false则不进行SQL组装
*@return
*/
booleanisEffective();
/**
*获取实际的value值
*@return
*/
ObjectgetValue();
}
如下是一个使用例子
Blogblog=query.andEq(Blog::getTitle,Query.filterNull(null))
.andIn(Blog::getId,Arrays.asList(1,2,3,4,5,6,7))
.andNotIn(Blog::getId,Query.filterEmpty(Collections.EMPTY_LIST))
.andNotEq(Blog::getId,Query.filterEmpty(""))
.andLess(Blog::getId,Query.filterEmpty(2))
.andGreatEq(Blog::getId,Query.filterEmpty(0)).single()
template查询publicListtemplate(Tt)根据模板查询,返回所有符合这个模板的数据库同上,mapper可以提供额外的映射,如处理一对多,一对一
publicTtemplateOne(Tt)根据模板查询,返回一条结果,如果没有找到,返回null
publicListtemplate(Tt,intstart,intsize)同上,可以翻页
publiclongtemplateCount(Tt)获取符合条件的个数
publicListtemplate(Classtarget,Objectparas,longstart,longsize)模板查询,参数是paras,可以是Map或者普通对象
publiclongtemplateCount(Classtarget,Objectparas)获取符合条件个数
翻页的start,系统默认位从1开始,为了兼容各个数据库系统,会自动翻译成数据库习俗,比如start为1,会认为mysql,postgres从0开始(从start-1开始),oralce,sqlserver,db2从1开始(start-0)开始。
然而,如果你只用特定数据库,可以按照特定数据库习俗来,比如,你只用mysql,start为0代表起始纪录,需要配置
OFFSET_START_ZERO=true
这样,翻页参数start传入0即可。
模板查询一般时间较为简单的查询,如用户登录验证
Usertemplate=newUser();
template.setName(...);
template.setPassword(...);
template.setStatus(1);
Useruser=sqlManager.templateOne(template);
通过sqlid查询,sql语句在md文件里publicListselect(StringsqlId,Classclazz,Mapparas)根据sqlid来查询,参数是个map
publicListselect(StringsqlId,Classclazz,Objectparas)根据sqlid来查询,参数是个pojo
publicListselect(StringsqlId,Classclazz)根据sqlid来查询,无参数
publicTselectSingle(Stringid,Objectparas,Classtarget)根据sqlid查询,输入是Pojo,将对应的唯一值映射成指定的target对象,如果未找到,则返回空。需要注意的时候,有时候结果集本身是空,这时候建议使用unique
publicTselectSingle(Stringid,Mapparas,Classtarget)根据sqlid查询,输入是Map,将对应的唯一值映射成指定的target对象,如果未找到,则返回空。需要注意的时候,有时候结果集本身是空,这时候建议使用unique
publicTselectUnique(Stringid,Objectparas,Classtarget)根据sqlid查询,输入是Pojo或者Map,将对应的唯一值映射成指定的target对象,如果未找到,则抛出异常
publicTselectUnique(Stringid,Mapparas,Classtarget)根据sqlid查询,输入是Pojo或者Map,将对应的唯一值映射成指定的target对象,如果未找到,则抛出异常
publicIntegerintValue(Stringid,Objectparas)查询结果映射成Integer,如果找不到,返回null,输入是object
publicIntegerintValue(Stringid,Mapparas)查询结果映射成Integer,如果找不到,返回null,输入是map,其他还有longValue,bigDecimalValue
注意,对于Map参数来说,有一个特殊的key叫着_root,它代表了查询根对象,sql语句中未能找到的变量都会在试图从_root中查找,关于_root对象,可以参考第8章。在Map中使用_root,可以混合为sql提供参数
指定范围查询publicListselect(StringsqlId,Classclazz,Mapparas,intstart,intsize),查询指定范围
publicListselect(StringsqlId,Classclazz,Objectparas,intstart,intsize),查询指定范围
beetlsql默认从1开始,自动翻译为目标数据库的的起始行,如mysql的0,oracle的1
如果你想从0开始,参考11章,配置beetlsql
翻页查询APIpublicvoidpageQuery(StringsqlId,Classclazz,PageQueryquery)
BeetlSQL提供一个PageQuery对象,用于web应用的翻页查询,BeetlSql假定有sqlId和sqlId$count,俩个sqlId,并用这来个来翻页和查询结果总数.如:
queryNewUser
===
select*fromuserorderbyiddesc;
queryNewUser$count
===
selectcount(1)fromuser
对于俩个相似的sql语句,你可以使用use函数,把公共部分提炼出来.
大部分情况下,都不需要2个sql来完成,一个sql也可以,要求使用page函数或者pageTag标签,这样才能同时获得查询结果集总数和当前查询的结果
queryNewUser
===
select
@pageTag(){
a.*,b.namerole_name
@}
fromuseraleftjoinb...
如上sql,会在pageQuery查询的时候转为俩条sql语句
selectcount(1)fromuseraleftjoinb...
selecta.*,b.namerole_namefromuseraleftjoinb...
如果字段较多,为了输出方便,也可以使用pageTag,字段较少,用page函数也可以.,具体参考pageTag和page函数说明.翻页代码如下
//从第一页开始查询,无参数
PageQueryquery=newPageQuery();
sql.pageQuery("user.queryNewUser",User.class,query);
System.out.println(query.getTotalPage());
System.out.println(query.getTotalRow());
System.out.println(query.getPageNumber());
Listlist=query.getList();
PageQuery对象也提供了orderBy属性,用于数据库排序,如"iddesc"
跨数据库支持如果你打算使用PageQuery做翻页,且只想提供一个sql语句+page函数,那考虑到跨数据库,应该不要在这个sql语句里包含排序,因为大部分数据库都不支持.page函数生成的查询总数sql语句,因为包含了oderby,在大部分数据库都是会报错的的,比如:selectcount(1)formuserorderbyname,在sqlserver,mysql,postgresql都会出错,oracle允许这种情况,因此,如果你要使用一条sql语句+page函数,建议排序用PageQuery对象里有排序属性oderBy,可用于排序,而不是放在sql语句里.
2.8版本以后也提供了标签函数pageIgnoreTag,可以用在翻页查询里,当查询用作统计总数的时候,会忽略标签体内容,如
selectpage("*")fromxxx
@pageIgnoreTag(){
orderbyid
@}
如上语句,在求总数的时候,会翻译成selectcount(1)fromxxx
如果你不打算使用PageQuery+一条sql的方式,而是用两条sql来分别翻页查询和统计总数,那无所谓
或者你直接使用select带有起始和读取总数的接口,也没有关系,可以在sql语句里包含排序
如果PageQuery对象的totalRow属性大于等于0,则表示已经知道总数,则不会在进行求总数查询
更新API添加,删除和更新均使用下面的API
自动生成sqlpublicvoidinsert(Objectparas)插入paras到paras关联的表
publicvoidinsert(Objectparas,booleanautoAssignKey)插入paras到paras对象关联的表,并且指定是否自动将数据库主键赋值到paras里,适用于对于自增或者序列类数据库产生的主健
publicvoidinsertTemplate(Objectparas)插入paras到paras关联的表,忽略为null值或者为空值的属性
publicvoidinsertTemplate(Objectparas,booleanautoAssignKey)插入paras到paras对象关联的表,并且指定是否自动将数据库主键赋值到paras里,忽略为null值或者为空值的属性,调用此方法,对应的数据库必须主键自增。
publicvoidinsert(Classclazz,Objectparas)插入paras到clazz关联的表
publicvoidinsert(Classclazz,Objectparas,KeyHolderholder),插入paras到clazz关联的表,如果需要主键,可以通过holder的getKey来获取,调用此方法,对应的数据库必须主键自增
publicintinsert(Classclazz,Objectparas,booleanautoAssignKey)插入paras到clazz关联的表,并且指定是否自动将数据库主键赋值到paras里,调用此方法,对应的数据库必须主键自增。
publicintupdateById(Objectobj)根据主键更新,所有值参与更新
publicintupdateTemplateById(Objectobj)根据主键更新,属性为null的不会更新
publicintupdateBatchTemplateById(Classclazz,Listlist)批量根据主键更新,属性为null的不会更新
publicintupdateTemplateById(Classclazz,Mapparas)根据主键更新,组件通过clazz的annotation表示,如果没有,则认为属性id是主键,属性为null的不会更新。
publicint[]updateByIdBatch(Listlist)批量更新
publicvoidinsertBatch(Classclazz,Listlist)批量插入数据
publicvoidinsertBatch(Classclazz,Listlist,booleanautoAssignKey)批量插入数据,如果数据库自增主键,获取。
publicintupsert(Objectobj),更新或者插入一条。先判断是否主键为空,如果为空,则插入,如果不为空,则从数据库按照此主健取出一条,如果未取到,则插入一条,其他情况按照主键更新。插入后的自增或者序列主健
intupsertByTemplate(Objectobj)同上,按照模板插入或者更新。
通过sqlid更新(删除)publicintinsert(StringsqlId,Objectparas,KeyHolderholder)根据sqlId插入,并返回主键,主键id由paras对象所指定,调用此方法,对应的数据库表必须主键自增。
publicintinsert(StringsqlId,Objectparas,KeyHolderholder,StringkeyName)同上,主键由keyName指定
publicintinsert(StringsqlId,Mapparas,KeyHolderholder,StringkeyName),同上,参数通过map提供
publicintupdate(StringsqlId,Objectobj)根据sqlid更新
publicintupdate(StringsqlId,Mapparas)根据sqlid更新,输出参数是map
publicint[]updateBatch(StringsqlId,Listlist)批量更新
publicint[]updateBatch(StringsqlId,Map[]maps)批量更新,参数是个数组,元素类型是map
直接执行SQL模板直接执行sql模板语句一下接口sql变量是sql模板
publicListexecute(Stringsql,Classclazz,Objectparas)
publicListexecute(Stringsql,Classclazz,Mapparas)
publicintexecuteUpdate(Stringsql,Objectparas)返回成功执行条数
publicintexecuteUpdate(Stringsql,Mapparas)返回成功执行条数
直接执行JDBCsql语句查询publicListexecute(SQLReadyp,Classclazz)SQLReady包含了需要执行的sql语句和参数,clazz是查询结果,如
Listlist=sqlManager.execute(newSQLReady("select*fromuserwherename=?andage=?","xiandafu",18),User.class);)
publicPageQueryexecute(SQLReadyp,Classclazz,PageQuerypageQuery)
StringjdbcSql="select*fromuserorderbyid";
PageQueryquery=newPageQuery(1,20);
query=sql.execute(newSQLReady(jdbcSql),User.class,query);
注意:sql参数通过SQLReady传递,而不是PageQuery。
更新publicintexecuteUpdate(SQLReadyp)SQLReady包含了需要执行的sql语句和参数,返回更新结果
publicint[]executeBatchUpdate(SQLBatchReadybatch)批量更新(插入)
直接使用ConnectionpublicTexecuteOnConnection(OnConnectioncall),使用者需要实现onConnection方法的call方法,如调用存储过程
Listusers=sql.executeOnConnection(newOnConnection(){
@Override
publicListcall(Connectionconn)throwsSQLException{
CallableStatementcstmt=conn.prepareCall("{?=callmd5(?)}");
ResultSetrs=callableStatement.executeQuery();
returnthis.sqlManagaer.getDefaultBeanProcessors().toBeanList(rs,User.class);
}
});
其他强制使用主或者从如果为SQLManager提供多个数据源,默认第一个为主库,其他为从库,更新语句将使用主库,查询语句使用从库库
可以强制SQLManager使用主或者从
publicvoiduseMaster(DBRunnerf)DBRunner里的beetlsql调用将使用主数据库库
publicvoiduseSlave(DBRunnerf)DBRunner里的beetlsql调用将使用从数据库库
对于通常事务来说只读事务则从库,写操作事务则总是主库。关于主从支持,参考17章
生成Pojo代码和SQ片段用于开发阶段根据表名来生成pojo代码和相应的sql文件
genPojoCodeToConsole(Stringtable),根据表名生成pojo类,输出到控制台.
genSQLTemplateToConsole(Stringtable),生成查询,条件,更新sql模板,输出到控制台。
genPojoCode(Stringtable,Stringpkg,StringsrcPath,GenConfigconfig)根据表名,包名,生成路径,还有配置,生成pojo代码
genPojoCode(Stringtable,Stringpkg,GenConfigconfig)同上,生成路径自动是项目src路径,或者src/main/java(如果是maven工程)
genPojoCode(Stringtable,Stringpkg),同上,采用默认的生成配置
genSQLFile(Stringtable),同上,但输出到工程,成为一个sql模版,sql模版文件的位置在src目录下,或者src/main/resources(如果是maven)工程.
genALL(Stringpkg,GenConfigconfig,GenFilterfilter)生成所有的pojo代码和sql模版,
genBuiltInSqlToConsole(Classz)根据类来生成内置的增删改查sql语句,并打印到控制台
sql.genAll("com.test",newGenConfig(),newGenFilter(){
publicbooleanaccept(StringtableName){
if(tableName.equalsIgnoreCase("user")){
returntrue;
}else{
returnfalse;
}
//returnfalse
}
});
第一个参数是pojo类包名,GenConfig是生成pojo的配置,GenFilter是过滤,返回true的才会生成。如果GenFilter为null,则数据库所有表都要生成
警告必须当心覆盖你掉你原来写好的类和方法,不要轻易使用genAll,如果你用了,最好立刻将其注释掉,或者在genFilter写一些逻辑保证不会生成所有的代码好sql模板文件
悲观锁lockSQLManager提供如下API实现悲观锁,clazz对应的数据库表,主键为pk的记录实现悲观锁
publicTlock(Classclazz,Objectpk)
相当于sql语句
select*fromxxxwhereid=?forupdate
lock方法必须用在事务环境里才能生效。事务结束后,自动释放
Tags:BeetSql下载,数据库管理工具,数据库
 欧.易下载交易平台Web3钱包 / 308.6MB / 2024-5-18
欧.易下载交易平台Web3钱包 / 308.6MB / 2024-5-18小编点评:用户最受欢迎且增长最快的交易平台,Web3钱包第一
下载 币.安下载交易平台 / 187.8MB / 2024-5-18
币.安下载交易平台 / 187.8MB / 2024-5-18小编点评:全球交易量第一的交易平台
下载 集福宝集ar五福神器浏览辅助 / 845.45MB / 2022-4-29 / WinAll, WinXP, Win7 / /
集福宝集ar五福神器浏览辅助 / 845.45MB / 2022-4-29 / WinAll, WinXP, Win7 / / 小编点评:集福宝集ar五福神器是一款2019年最.
下载 liwo视频转换视频转换 / 288.98MB / 2022-9-8 / WinAll / /
liwo视频转换视频转换 / 288.98MB / 2022-9-8 / WinAll / / 小编点评:liwo视频转换可以用来给我们提供.
下载 BluRip一键将蓝光碟转成MKV格式视频转换 / 91.18MB / 2020-2-9 / WinXP, WinAll / /
BluRip一键将蓝光碟转成MKV格式视频转换 / 91.18MB / 2020-2-9 / WinXP, WinAll / / 小编点评:这个BluRip的软件是能够一键将.
下载 厂家惠QQ拉好友入群软件QQ其它 / 749.48MB / 2011-9-15 / WinAll / /
厂家惠QQ拉好友入群软件QQ其它 / 749.48MB / 2011-9-15 / WinAll / / 小编点评:厂家惠QQ拉好友入群软件是一款一键自.
下载 魔兽地图:保护领地-终极版游戏地图 / 126.45MB / 2022-7-22 / WinAll, WinXP, Win7, win8 / /
魔兽地图:保护领地-终极版游戏地图 / 126.45MB / 2022-7-22 / WinAll, WinXP, Win7, win8 / / 小编点评:保护领地-终极版是一张标准的防守地图,本图一.
下载 云里关键词挖掘大师浏览辅助 / 30.44MB / 2021-8-25 / WinXP, win7, WinAll / /
云里关键词挖掘大师浏览辅助 / 30.44MB / 2021-8-25 / WinXP, win7, WinAll / / 小编点评:云里关键词挖掘大师是一款完全免费的长尾关.
下载 ADCleaner视频去广告软件浏览辅助 / 693.40MB / 2014-12-23 / WinAll / /
ADCleaner视频去广告软件浏览辅助 / 693.40MB / 2014-12-23 / WinAll / / 小编点评:ADCleaner是一款免费专业净网.
下载 无量百度网盘提取码工具浏览辅助 / 459.66MB / 2021-3-28 / WinAll / /
无量百度网盘提取码工具浏览辅助 / 459.66MB / 2021-3-28 / WinAll / / 小编点评:无量百度网盘提取码工具是一款用于加.
下载 蔚蓝主页浏览辅助 / 967.77MB / 2018-6-4 / WinAll, WinXP, Win7, win10 / /
蔚蓝主页浏览辅助 / 967.77MB / 2018-6-4 / WinAll, WinXP, Win7, win10 / / 小编点评:蔚蓝主页是一款标签页的工具,这款全.
下载 仙之侠道Ⅱ活动专用版游戏地图 / 530.99MB / 2012-7-14 / WinXP, WinAll / /
仙之侠道Ⅱ活动专用版游戏地图 / 530.99MB / 2012-7-14 / WinXP, WinAll / / 小编点评:比赛所用地图版本为【仙之侠道ⅡPK活.
下载 幽灵讨伐队游戏地图 / 744.92MB / 2016-6-21 / Vista, WinXP, win7 / /
幽灵讨伐队游戏地图 / 744.92MB / 2016-6-21 / Vista, WinXP, win7 / / 小编点评:在异次元的某个地方有一个奇怪的地方.
下载 dota imba3.86游戏地图 / 85.80MB / 2021-10-13 / WinAll, WinXP / /
dota imba3.86游戏地图 / 85.80MB / 2021-10-13 / WinAll, WinXP / / 小编点评:3.86AI更新日志:英雄:圣堂刺.
下载 Dota CotT 诸神之战游戏地图 / 789.9MB / 2013-10-16 / WinAll, WinXP / /
Dota CotT 诸神之战游戏地图 / 789.9MB / 2013-10-16 / WinAll, WinXP / / 小编点评:DotaCotT诸神之战:本图需要1.2.
下载 战时舰队司令部游戏下载-战时舰队司令部手游下载v1.67 安卓最新版
战时舰队司令部游戏下载-战时舰队司令部手游下载v1.67 安卓最新版 武战乾坤1.1.1
武战乾坤1.1.1 七之物语汉化版下载-七之物语中文版下载v1.0 安卓版
七之物语汉化版下载-七之物语中文版下载v1.0 安卓版 小小部落战争游戏-小小部落战争手机版(暂未上线)v1.0.1 安卓版
小小部落战争游戏-小小部落战争手机版(暂未上线)v1.0.1 安卓版 aporia内购破解版下载-aporia无限金币版下载v1.6 安卓汉化版
aporia内购破解版下载-aporia无限金币版下载v1.6 安卓汉化版 魔兽英雄传2破解版下载-魔兽英雄传2内购破解版下载v1.10.150630 安卓版保卫蛋蛋中文破解版下载-保卫蛋蛋内购破解版下载v1.8 安卓无限金币版格斗三国志游戏下载-格斗三国志手机版下载v1.7 安卓版
魔兽英雄传2破解版下载-魔兽英雄传2内购破解版下载v1.10.150630 安卓版保卫蛋蛋中文破解版下载-保卫蛋蛋内购破解版下载v1.8 安卓无限金币版格斗三国志游戏下载-格斗三国志手机版下载v1.7 安卓版 天下无双3d游戏下载-天下无双3d手游下载v5.2.0 安卓最新版
天下无双3d游戏下载-天下无双3d手游下载v5.2.0 安卓最新版 怪鱼合并战争最新版下载-怪鱼合并战争游戏(the fish vs grimaze)下载v2.0 安卓版霸王之业战国野望手游下载-霸王之业战国野望官方版下载v1.0.1 安卓最新版
怪鱼合并战争最新版下载-怪鱼合并战争游戏(the fish vs grimaze)下载v2.0 安卓版霸王之业战国野望手游下载-霸王之业战国野望官方版下载v1.0.1 安卓最新版 qb音乐下载免费-QB音乐APP下载v1.1 安卓版
qb音乐下载免费-QB音乐APP下载v1.1 安卓版
魔兽地图:狮子王3.7
 游戏地图 / 265.20MB / 2019-6-24 / WinAll, WinXP / / 下载
游戏地图 / 265.20MB / 2019-6-24 / WinAll, WinXP / / 下载
魔兽地图:你的世界v1.1测试版
 游戏地图 / 418.30MB / 2019-1-22 / WinAll, WinXP, Win7, win8 / / 下载
游戏地图 / 418.30MB / 2019-1-22 / WinAll, WinXP, Win7, win8 / / 下载魔界降临创世纪1.4.7
游戏地图 / 227.81MB / 2010-11-29 / WinAll, WinXP, Win7, win8 / / 下载
种族v4.54
游戏地图 / 263.50MB / 2020-11-28 / WinAll, WinXP, Win7, win8 / / 下载众神降临之弹丸传说2.9.8【隐藏英雄密码】
 游戏地图 / 998.8MB / 2019-4-24 / WinAll, WinXP, Win7, win8 / / 下载
游戏地图 / 998.8MB / 2019-4-24 / WinAll, WinXP, Win7, win8 / / 下载圣魔之血7.2【隐藏英雄密码】
游戏地图 / 678.73MB / 2015-6-23 / WinAll, WinXP, Win7, win8 / / 下载
MVP V1.0.0下载
音乐播放 / 736.52MB / 2018-9-15 / Win8,Win7,WinXP / 英文 / 免费软件 下载
飞信多用户登陆工具V2.0.0.下载
聊天工具 / 500.97MB / 2012-4-13 / Win8,Win7,WinXP / 简体中文 / 免费软件 下载
LswTech MP3 Player英文绿色免费版V2.2下载
音乐播放 / 357.30MB / 2010-8-3 / Win8,Win7,WinXP / 简体中文 / 免费软件 下载
IC CRYPT V1.0下载
聊天工具 / 312.15MB / 2012-3-13 / Win8,Win7,WinXP / 英文 / 免费软件 下载
顶峰-DVD至iPod转换器试用版(顶峰DVD至iPod转换器免费下载)V7.1下载
视频转换 / 543.69MB / 2012-6-4 / Win8,Win7,WinXP / 简体中文 / 免费软件 下载
远方定时播放音乐软件 v3.4
音乐播放 / 372.19MB / 2021-10-4 / WinAll / 简体中文 / 共享软件 下载
长风高速计算器V1.0.0.0下载
计算器类 / 586.66MB / 2011-6-15 / Win8,Win7,WinXP / 简体中文 / 免费软件 下载



 易杰DVD转MP4转换器下载 v8.3
易杰DVD转MP4转换器下载 v8.3  iFun Video Converter(VR视频转换)V1.0.2.2824免费版下载
iFun Video Converter(VR视频转换)V1.0.2.2824免费版下载  植物战僵尸王2破解版下载-植物战僵尸王2破解版无限钻石版下载v10.0.3 安卓版
植物战僵尸王2破解版下载-植物战僵尸王2破解版无限钻石版下载v10.0.3 安卓版 狮子骑士团纷乱战争手机版下载-狮子骑士团纷乱战争手游下载v1.0 安卓版
狮子骑士团纷乱战争手机版下载-狮子骑士团纷乱战争手游下载v1.0 安卓版 帝王传奇手游官方-帝王传奇手游服务端(暂未上线)v2.0.2 安卓版
帝王传奇手游官方-帝王传奇手游服务端(暂未上线)v2.0.2 安卓版 现代海战破解版下载-现代海战内购破解版下载v1.1.7 安卓无限金币版
现代海战破解版下载-现代海战内购破解版下载v1.1.7 安卓无限金币版 bandlab安卓版下载中文版-bandlab app下载v10.67.2 最新汉化版
bandlab安卓版下载中文版-bandlab app下载v10.67.2 最新汉化版 经典耐玩的传奇手游
经典耐玩的传奇手游 儿童休闲益智游戏
儿童休闲益智游戏 模拟搬家游戏
模拟搬家游戏 格斗拳击游戏
格斗拳击游戏 自由度高的单机游戏
自由度高的单机游戏 装备保值的传奇游戏
装备保值的传奇游戏 可以组队开荒的手游
可以组队开荒的手游 有合击技能的三国手游
有合击技能的三国手游